
Rispondo ad una richiesta di cosa di computer. Mi hanno chiesto perché a volte compaiano sugli schermi di PC e cellulari dei caratteri “strani”. Comprensibilmente, nella domanda si menziona la crittografia (un procedimento che rende i testi leggibili solo da chi è in possesso di una certa chiave). In questo caso però non c’entra nulla: per capire perché succede bisogna comprendere cos’è la codifica dei caratteri.
Capire cos’è la codifica dei caratteri non è semplice. Assieme alla crittografia a chiave privata, è l’argomento che ho più difficoltà a spiegare durante i corsi e le lezioni private. Tuttavia posso assicurarti che si tratta di una nozione abbastanza semplice. Partiamo dalla base: cos’è un computer? È un apparecchio elettronico che esegue programmi. Ad esempio, Microsoft Word è un programma per PC.
I programmi manipolano dati, racchiusi all’interno di contenitori chiamati file. Ogni file ha un formato specifico. Ad esempio, i file .txt sono file di testo semplice, mentre i file .doc e .docx sono file di testo formattato (ovvero testo arricchito con grassetti, sottolineature, corsivi ed altre informazioni di stile). A prescindere dal formato, i file di testo contengono caratteri, ed i caratteri vanno “codificati” per essere resi leggibili dai computer.
Perché? Per motivi tecnici che sarebbe lungo spiegare, i computer sono in grado di manipolare (leggere e scrivere) solo numeri. Per far si che possano manipolare anche caratteri, bisogna convertirli in numeri usando una tabella specifica. Ne esiste una creata nel 1963, e si chiama tabella ASCII: associa un numero decimale ad un carattere.
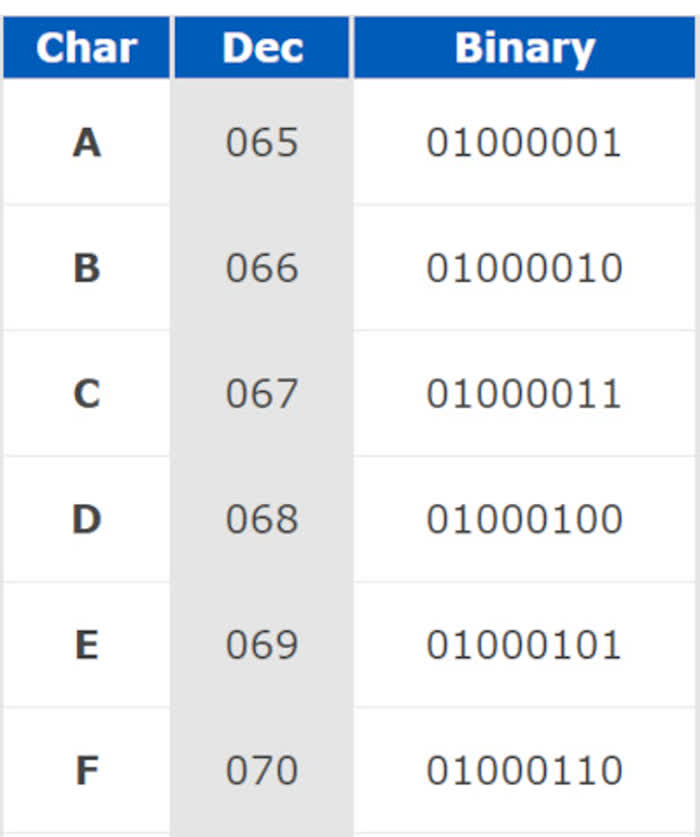
Questa tabella non include i caratteri cirillici, cinesi, giapponesi ed arabi. Non include nemmeno le lettere accentate (à, è, é, ì, ò ed ù). Per cui è stata inventata una nuova tabella che estende ASCII, chiamata “Unicode“. A volte i computer cercano di interpretare i caratteri Unicode con la tabella ASCII, generando così caratteri illegibili.